GPU execution timing basics in Vk and DX12
Published: 19-01-2023This is just a quick post about using timestamp queries in Vulkan (and DX12) to measure the GPU execution times. We start with a bit of motivation, show some use cases, then dive right into the Vulkan and DX12 functions, and conclude with a series of snippets of how to use them in action.
Frame timing basics
When measuring frame times, the basic setup is to measure the time elapsed from the start of a frame to the start of the next frame. This can give us some idea of the frame length but in reality, it usually tells just half of the story and may not even be representative of time spent doing useful work.
Let's consider a basic double-buffered setup where while frame N is being rendered on the GPU, the CPU processes
update and records command buffers for frame N+1. Since we're double buffering, we keep two sets of resources (command
buffers, pools, semaphores...) and there are two (three) scenarios of how the CPU/GPU synchronization can end up.
ℹ️ We are considering a case where we work as fast as possible - not a fixed frame/vsync scenario
- CPU finishes first and waits for the GPU - we're GPU bound
- GPU finishes first and stays idle before more work is submitted - we're CPU bound
- CPU and GPU take the same time - this never really happens in practice for obvious reasons.
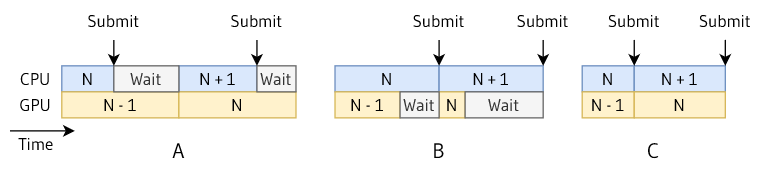
If we time our CPU frames once per frame at the beginning including the potential Wait for the GPU. We can see that in
case A we are timing the GPU execution. And in case B we have no idea how long the GPU takes by just measuring the
CPU time. Therefore, to get a basic knowledge of our frame timings without using a profiler we need to measure the CPU
and GPU execution separately.
ℹ️ I will be talking only about time, not FPS since I think FPS should be only a player-facing number because they are not a useful metric to track during development. Just remember your target FPS in milliseconds and never mention FPS again. Sentences such as "The game now runs 10 FPS faster" make no sense whatsoever since the speedup from 130 FPS to 140 FPS is completely different than from 20 FPS to 30 FPS. Therefore, always specify milli/micro/nano-seconds "The game now runs 1.3ms faster" means always the same thing.
Using timestamps
To perform basic CPU timings we use functions such as QueryPerformanceCounter on Windows to get a timestamp before and
after a measured operation. To get the elapsed time in nanoseconds, we subtract the timestamps and divide the result by
the counter frequency obtained from QueryPerformanceFrequency. For more details see
MSDN.
Fortunately, the process on the GPU is conceptually very similar. The main difference is that the operations we want to measure happen on the GPU timeline. That means we need to insert our timestamp commands (called queries) into a command list, wait for it to finish and then retrieve our data to a CPU-readable memory. After that, we can again subtract them and divide them by the counter frequency to get elapsed time in nanoseconds.
ℹ️ The counter frequency we talk about is independent of the CPU and GPU core frequencies and does not have to be queried more than once. If it was bound to the current clock getting precise elapsed time measurements would be incredibly difficult if not straight impossible as the OS would have to save the CPU frequency changes in time and we would have to get this data between our timestamps to be able to compute the elapsed number of "tics".
Timestamp use-cases
The most basic use-case of timestamps is to measure the whole frame GPU execution. That is simply done by recording one timestamp at the start of the first command buffer and one timestamp at the end of the very last command buffer. If our application uses multiple queues (async compute, copy...), we have to make sure to subtract timestamps executed on the same queue unless we explicitly control the order of operations on the GPU. When timing the whole frame, we also need to make sure that the command lists we think are first and last are that since commands on other queues may take longer.
A more interesting use case is to take this one step further and measure the execution of individual passes or operations within them. This way, we can easily create a simple scope-based (instrumentation) profiler. Once again, care has to be taken when dealing with async compute queues since we cannot just sum up all our scopes and stack them on top of each other to get frame time. Such a profiler can be very useful as a first resort for quickly investigating performance in a game right when it happens or as a tool for QA/autotesting machines to provide useful data.
The usage of course does not end here. If we wanted to go wild, we could for example keep some scopes even in the shipped game and determine how we build a frame in runtime based on the previous frame results. One such use case could be to base render graph pass reordering based on the timings we get. Another use case could be to report the performance impact of various settings to players on their specific hardware so they could tweak the settings to best fit them.
ℹ️ When timing your frames, keep in mind that the GPU clock may be rapidly changing and unless the GPU is highly utilized (for example in CPU-bound scenarios) it may underclock itself to save power. This means that measurements may look longer not because of imprecise timestamps or slow code but just because the GPU has no reason to finish in 1ms instead of 2ms if it will afterward remain IDLE for 10ms waiting for the CPU anyway.
Timestamp queries in Vulkan and DX12
Now for the implementation details with a disclaimer to take this just as a reference and to always read the docs that are linked at each function name.
Querying timestamps in both Vulkan and DX12 is very similar. In
both APIs we allocate a pool (heap) of N timestamps that are referenced by indices from 0 to N-1. The basic
steps we need to do on Vulkan are as follows:
- Query the timestamp frequency (once, for example on startup)
vkGetPhysicalDevicePropertiesto getVkPhysicalDeviceProperties.limits.timestampPeriod - Allocate a timestamp query pool
vkCreateQueryPoolof typeVK_QUERY_TYPE_TIMESTAMP - Reset the query pool
vkCmdResetQueryPool
vkResetQueryPool- this requiresVkPhysicalDeviceHostQueryResetFeatures- core since 1.2 (beforeVK_EXT_host_query_reset) - Record timestamp commands
vkCmdWriteTimestamp - Get timestamp data to CPU visible memory either on the CPU or GPU timeline
vkGetQueryPoolResults
vkCmdCopyQueryPoolResults - Wait for the command list to finish before reading the values
May be necessary before the previous step ifvkGetQueryPoolResultsis used without availability or wait flags - Reset the query pool to be able to reuse it
Matching DX12 functions are
ID3D12CommandQueue::GetTimestampFrequencyID3D12Device::CreateQueryHeapof typeD3D12_QUERY_HEAP_TYPE_TIMESTAMPID3D12GraphicsCommandList::EndQuery
Since timestamp queries mark a single point in time but share the interface with other queries we have to callEndQueryonly.ID3D12GraphicsCommandList::ResolveQueryData
vkCmdCopyQueuePoolResultsequivalent.vkGetQueryPoolResultsdoes not have an equivalent in DX12.
In DX12 the query heap does not have to be reset, however, resolving queries that are not initialized is invalid and may cause device removal. That is very different form Vulkan, which specifies that available queries are copied (does not talk about unavailable ones) and the availability can be queried along with the results.
Vulkan code
Now to get into even more specifics here are some snippets of Vulkan code demonstrating the concepts we talked about.
// --- Startup ---
// Query timestamp period. We will multiply by this number instead of dividing since period = (1 / frequency).
float timestampPeriod;
vkGetPhysicalDeviceProperties(vkPhysicalDevice, &vkPhysicalDeviceProperties);
timestampPeriod = limits.timestampPeriod;
// Create query pool
VkQueryPoolCreateInfo poolCreateInfo{ VK_STRUCTURE_TYPE_QUERY_POOL_CREATE_INFO };
poolCreateInfo.queryType = VK_QUERY_TYPE_TIMESTAMP;
poolCreateInfo.queryCount = totalQueryCount;
VkQueryPool timestampQueryPool[FRAMES_IN_FLIGHT]; // Double-buffer query pools if necessary
for (int i = 0; i < FRAMES_IN_FLIGHT; ++i)
{
vkCreateQueryPool(vkDevice, &poolCreateInfo, nullptr, timestampQueryPool[i]);
vkResetQueryPool(vkDevice, timestampQueryPool[i], 0, totalQueryCount); // Reset all queries
}
To measure the whole frame execution, we want to put one query at the start of the first command list and one at the end of the last command list. Let's assume for simplicity we have only one command list for the whole frame.
// Double buffer query indices in case they don't happen to be the same every frame
uint32 lastUsedQuery = 0;
uint32 startFrameQuery[FRAMES_IN_FLIGHT];
uint32 endFrameQuery[FRAMES_IN_FLIGHT];
uint64* results; // Buffer large enough to store all timestamps
// --- Per frame --
// Reset and get results - we should be sure that the GPU is done at this point, for example by waiting on a semaphore
// VK_QUERY_RESULT_64_BIT to get 64 bit timestamps
vkGetQueryPoolResults(vkDevice, pool, 0, queryCount, sizeof(uint64) * queryCount, results, sizeof(uint64), VK_QUERY_RESULT_64_BIT);
vkResetQueryPool(vkDevice, pool, 0, queryCount);
lastUsedQuery = 0;
// Start new frame
beginFrameQuery[frameIndex] = lastUsedQuery++;
vkCmdWriteTimestamp(cb, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, pool, beginFrameQuery[frameIndex]);
// To get previous frame's GPU execution time do this anywhere during current frame
uint64 elapsed = results[endFrameQuery[lastFrameIndex]] - results[beginFrameQuery[lastFrameIndex]];
uint64 elapsedNanoseconds = (uint64)(elapsed * timestampPeriod);
// Record commands to command buffer
endFrameQuery[frameIndex] = lastUsedQuery++;
vkCmdWriteTimestamp(cb, VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT, pool, endFrameQuery[frameIndex]);
// Execute command buffer and repeat Per frame loop
On shutdown don't forget to destroy the query pool if you want to keep your validation log clean.
// --- Shutdown ---
vkDestroyQueryPool(r->vkDevice_, r->timestampQueryPool_[i], nullptr);
Conclusion
Timestamp queries are a very useful tool and in my opinion GPU execution time should be right next to the CPU execution time in every engine/game. Even though it does not replace regular profiling sessions and individual profiling of one's changes, I consider it a bare minimum to have basic frame stats always visible and tracked during development to detect performance regressions and hitches as soon as possible.