Aliasing transient textures in DirectX 12
Published: 05-03-2022Modern renderers often write to many textures that are used for intermediate results or only briefly during a frame. For example, HBAO with its multiple passes may need several "scratch" textures internally or render targets of cascaded shadow maps that are used only to a certain point in a frame and may no longer be needed later during post-processing.
When we have two such textures that are not used at the same time on the GPU we could save memory by either reusing one texture for both cases or using multiple textures that are mapped to the same memory since only one of them will be used at a time. I call these "temporary textures" transient resources/textures1.
In this post, I describe how to make a simple cache to reuse transient resources and how to improve this cache by using resource memory aliasing in DirectX 12 to further reduce the memory footprint. It is meant as an introduction to the problematics, however, some knowledge of DX11 and DX12 is assumed. Let's say this is something I'd like to read when I was implementing DX12 for the first time.
Resource-level caching
First, let's think about an API for a simple cache that could work even in a DX11 context, where we share only
resources/resource views. By resource, I mean D3D11Texture or D3D12Resource, and resource views are descriptors on
top of these such as D3D11RenderTargetView or UAV D3D12_CPU_DESCRIPTOR_HANDLE.
The cache needs to conceptually support two operations, one to get a texture of a given specification out (either
already existing or newly allocated), and another one to return the texture back to the cache for later reuse. We will
call these Allocate and Release respectively.
Furthermore, transient textures can be in one of two states, Used or Ready. Textures that are Ready can be
returned by Allocate. Used marks that a texture cannot be allocated now since someone is using it already and it
must be released (must be in the Ready state) before it can be returned from Allocate again. We can imagine the
Used textures as not being in the cache at all (Allocate just erases them from the cache and Release puts them
back in) but using two distinct states like this will simplify the transition to a custom memory allocation scheme
later.
void Release(TransientResourceCache* cache, TextureEntry* texture)
{
MarkAsReady(texture);
}
Release has a simple job of marking an allocated texture Ready so it can be reused again.
TextureEntry* Allocate(TransientResourceCache* cache, const TextureKey& key)
{
TextureEntry* texture = LookupTexture(cache, key); // Try to lookup already existing texture from hashtable that is not Used
if (!texture)
{
texture = CreateTexture(key); // Create new DirectX resource
StoreTexture(cahce, texture); // Save to hashtable for later lookups
}
MarkAsUsed(texture);
return texture;
}
Allocate takes as an argument TextureKey which is a description of a texture we want to get from the cache. It may
include information such as width, height, format, usage - render target (RT), unordered access view (UAV), etc. We may
get away with specifying fewer parameters if we for example don't store UAVs but only RTs in our cache. Based on this
key, it first tries to find an already existing texture in the internal hashtable that matches the key and is not
Used. If there is no such texture we need to go and create a new one based on the specification and save it in the
cache. Now that we have a valid texture in any case we can mark it as Used so it cannot be returned again until it is
released and lastly, we return it.
ℹ️ The internal hashtable (or similar data structure) needs to support storing multiple textures with the same key since it is not unusual that one would need multiple identical textures to perform copies from one to the other etc.
This cache does not take into account any multi-threading and would not work well in the context of multi-threaded command list recording. The cache is inherently single-threaded as we assume there is one timeline of CPU instructions that will later result in one timeline of GPU command lists. Or more precisely, all operations accessing the cache will run in the same order on CPU as on the GPU and never in parallel on the CPU side. That is fine to explain the texture caching and memory aliasing concepts. To achieve fully parallel command list recording we would need more information about the command lists we will record and their expected texture cache usage beforehand.
ℹ️ We can still achieve good parallel command list recording on the CPU side. The only thing we need to ensure is that the render passes using the cache run in series. But any other render pass not using the cache can be recorded in parallel to every other render pass.
Using this cache and reusing resources is already a great improvement compared to creating and storing textures in each system separately. Now let's see what manual memory management brings us.
Memory aliasing
The main problem with resource-level caching is that we can reuse resources only if they match exactly. We could improve this by setting viewport when rendering to RTs but to go all the way we will reuse the underlying resource memory directly. This makes the resources relatively light-weight and their creation is fast if we already have preallocated memory compared to the older APIs where we had to rely on the driver to guess our usage and do this for us (or hide latency by executing operations on its separate thread).
In DX12, resource creation and memory allocation are (potentially2) two steps. A continuous chunk of memory we can allocate from the API is called heap in DX12. When creating a resource we give it a pointer to memory somewhere in the heap where the resource should start. This gives us the flexibility to point two resources to overlapping regions in memory as long as the resources don't use the memory at the same time. That generally means only one of the resources is active and can be read from/written to. When we start using the memory from a different resource - when a different resource starts being active, we need to indicate this to DX12 with an aliasing barrier that will ensure all operations with the old resource finish before operations with the new one begin. We also need reinitialize the currently active resource which will init its metadata.
ℹ️ Each time a resource activates we treat its memory as garbage. DX12 allows us to preserve the contents of the memory while aliasing in some cases in form of data inheritance3 but this is not useful for us.
Technical details with specific D3D12 objects and functions are provided later but now let's see how to use these concepts to improve our transient resource cache.
Adding memory allocator
The user-facing code will be identical to our simple resource-level caching as it is easy to use and we can hide all the complexity in the resource creation itself. This will also be beneficial if we want to support the older APIs at the same time. For simplicity, we'll start by assuming we know the highest possible memory usage of transient resources and allocate a single heap of that size. Our allocator will sub-allocate its own separate allocations from this heap. To avoid confusion, unless noted otherwise, when I talk about allocations I mean the sub-division of the heap.
Every transient resource has an associated allocation and each allocation can be in one of three states Used, Ready,
or Inactive. The first two states are analogous to the states on the resource level. The new Inactive state
indicates that this resource cannot be immediatelly reused as it is not the active resource using given memory. That
means there is at least one other resource in Used or Ready states that overlaps in memory with the Inactive
resource. To better illustrate the concept let's see the allocator in action.
On the image, memory addresses go from left to right and separate blocks are allocations. Each row is a snapshot of a
state of the allocator, there are usually multiple actions between two rows. R[n] indicates a resource residing in the
given allocation. Multiple allocations stacked on top of each other mark their aliasing in memory, there is no limit on
how many allocations can alias.
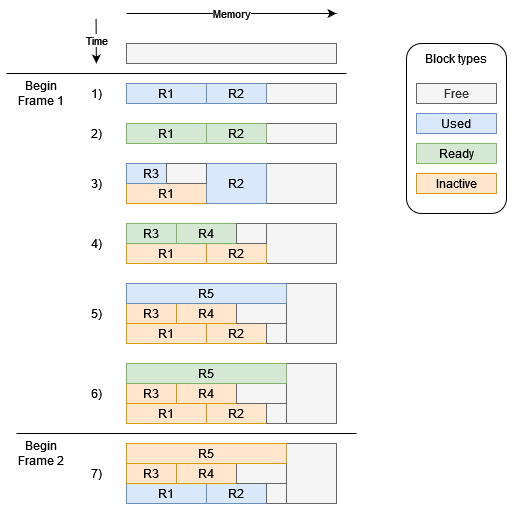
We start just with the empty heap. Let's describe what happens in each state one by one.
- Two resources
R1andR2are allocated from the cache and both are used at the same time. Releasewas called on bothR1andR2marking themReady.R3is allocated and sinceR1is not used we can reuse its memory. We also start usingR2again.- We skipped a few operations where
R4was used and is now ready withR3. - We need to allocate
R5which is bigger than any other resource, however, no resources are used so we can overlap all existing allocations and only slightly increase the maximum memory usage instead of almost doubling it. - This is the state at the end of Frame 1.
- Unless settings are changed, frames tend to be similar, so at the beginning of the second frame we do the same
operations and we again need
R1andR2. Since noUsedresources overlap these two we can just take and use the very same resources again.
Now to describe the algorithm more formally, let's specify the state transitions. New allocation starts in the Used
state as we want to use it right away. When a resource is returned to the cache the associated allocation goes to the
Ready state because it still "owns" the memory and no additional work needs to be done to use the associated resource
again (except for asking the cache for it). To get to the Inactive state, we need multiple resources overlapping in
memory. When creating a new resource we look for memory where to put it, the only memory we consider occupied is where
Used allocations are. When a large enough free block in the heap is found, new allocation is created and we need to
check if this allocation overlaps with any other allocations in the Ready state because these allocations currently
"own" the memory. If we find any Ready allocations we need to transfer the memory ownership from them to our new
allocation using aliasing barriers, making them Inactive. Aliasing barriers are also needed if we want to start using
already existing resource that is Inactive. This resource may alias with one or more Ready resource (if it would
alias with a Used resource we could not use it). Since the Ready resource owns the memory aliasing barrier is
needed.
ℹ️ Observe that for each memory address there can be always at most one resource in a non-Inactive (Used or Ready)
state at a time.
Implementation details
To make our allocator work we need to respect the memory aliasing and resource allocation rules of DX12. This section shows some key function calls and discusses possible modification of the allocator if the "high memory mark" is not known beforehand.
Memory allocation and alignment
The key functions for allocating memory and creating resources in the DX12 are
ID3D12Device::CreateHeap
that allocates a chunk of memory where we can then create resources with
ID3D12Device::CreatePlacedResource.
While creating a heap, take note of its alignment. The alignment of the whole heap should be as large as the largest
alignment of the resources we want to store in it. For example MSAA textures need 4MB alignment whereas regular ones
are fine with 64KB. If you know that you'll store only "small" MSAA or regular textures, you can use an alignment of
64KB or 4KB respectively4.
⚠️ The sub-allocations also need to respect the alignment requirements of their textures. So if we want to
combine small, regular, and MSAA textures in the same heap we will need to take care and align their allocations
properly.
Aliasing barriers
To mark when we switch the resource that "owns" a piece of memory and to avoid overwriting the old resource before we
finish reading it, DX12 provides us with aliasing barriers.
D3D12_RESOURCE_ALIASING_BARRIER
contains two fields of type ID3D12Resource* - pResourceBefore and pResourceAfter which indicate between which two
resources we want to switch. The barrier is used as any other barrier and is a part of the
D3D12_RESOURCE_BARRIER
structure. This also means we can and should batch as many barriers as possible in a call to
ResourceBarrier.
In our case, it means that we will first gather all resources in Ready state that alias with the resource we want to
use and submit all the aliasing barriers together.
ℹ️ Both pResourceBefore and pResourceAfter can be null, which forces the API to assume that there can be any
resource in place of the null argument which may result in a rather pessimistic barrier.
Resource initialization
Creating resources and allocating memory are not the only two steps in DX12 one has to take to end up with a valid resource. Even if we just create placed resources in reused memory, this memory may contain garbage. The same goes for memory aliasing where we view the memory as if it was a different resource. This is fine for regular textures without metadata but DX12 specifies that depth stencil and render target resources need to be initialized before any other operation is performed on them. There are three allowed ways of initialization.
- A Clear operation; for example
ClearRenderTargetVieworClearDepthStencilView. - A
DiscardResourceoperation. - A Copy operation; for example
CopyBufferRegion,CopyTextureRegion, orCopyResource.
In our case we want the resource to "just work" with the least amount of overhead possible; therefore, we choose
DiscardResource
as it will only reinitialize the metadata of a resource.
⚠️ Forgetting to initialize render targets may lead to weird bugs. This happened to me when first implementing DX12 and
switching from my "initial" implementation where all resources were allocated with CreateCommittedResource to a more
production-ready implementation using Placed resources and sub-allocating. Everything worked except for MSAA render
targets that for some reason made some triangles flicker. Not knowing what's the culprit I kept them as committed, only
to discover my mistake when re-reading the documentation some weeks later.
Putting it all together
Now that we have all the bits and pieces let's see how to fit it all together in a pseudo-implementation of the
MarkAsUsed function that is called when we found a suitable resource that we want to return from the cahce and start
using.
void MarkAsUsed(TransientResourceCache* cache, TextureEntry* texture)
{
// Texture can either be found inactive in cache from before or newly allocated this check
// should conver both. The remaining case is that the texture is Ready and can be used right away.
if (IsInactive(texture))
{
// Gather aliasing barriers
for (TextureEntry* other : cache->m_ReadyResources)
{
if (IsOverlapping(texture, other))
{
AddAliasingBarrier(texture, other)
SetInactive(other);
}
}
// The order is not specified well by the spec, it says that the first operation needs to be initialization
// however it does not make much sense to initialize memory if we did not indicate that we want to use it
// Hence this seems like the more reasonable order that worked for me in practice
SubmitAliasingBarriers();
if (NeedsInit(texture))
DiscardResource(texture);
}
SetUsed(texture);
}
Allocation strategy for multiple heaps
Just to briefly touch on one of the problems that were hand-waved above, what if we don't know our memory usage beforehand? This turns out to be a relatively hard problem but I'll at least sum some of my lessons learned.
One idea is to allocate the memory in chunks with the following simple algorithm.
constexpr size_t MIN_ALLOCATION_SIZE = 128 * 1024 * 1024; // 128 MB, can be anything really
// This ignores alignment for simplicity
Memory* AllocateMemory(size_t size)
{
// Look for space in existing heaps
Memory* memory = TryFindFreeSpace(size);
// No chunk big enough found, we need to allocate a new heap
if (!memory)
{
// Avoid allocating too small chunks to improve reusability
AllocateNewHeap(Min(size, MIN_ALLOCATION_SIZE));
// This now has to succeed as the new heap must be big enough but can be bigger
memory = FindFreeSpaceInNewHeap(size);
}
return memory;
}
The key concept is that by allocating bigger heap we improve the potential for their future reuse by different
resources. This is to combat a sequence of allocations such as 4, 5, 6, 7. If we allocated some minimum size
heap (8MB) first all these allocations could alias with each other. If we allocate just the precise size we will end
up with 4 small heaps of total size 4 + 5 + 6 + 7 = 22.
However in practice, this did not seem to work so well. What happened was that we ended up wasting space at the end of
many of the "min size" heaps. E.g. we got requests for two textures of 140 MB and 120 MB and our
MIN_ALLOCATION_SIZE was set to 256 MB which resulted in two 256 MB heaps that were half full. One could assume
that there would be smaller textures that would fill the rest of the heaps but that did not turn out to be the case with
our renderer. Therefore, it ended up being better to always allocate the exact size requested. Sometimes there may be
single-purpose heaps but they are better than having big half-empty heaps. We could of course try to hand tune the min
size but at that point, it would be probably better to measure the highest usage for each resolution and hardcode that.
Now to address the other extreme, if we know that the textures are temporary it should be possible to just allocate what we need and at the end of the frame sum the sizes of all the heaps, destroy them, and allocate one heap big enough for all the textures to fit effectively discovering the highest memory usage dynamically. There are two problems with this approach as described here. First, we cannot destroy the resources while still being used by the GPU, we need to delay the destruction which will effectively double our transient resource memory usage for a moment. Second, we must consider that when this happens the VRAM can be already quite fragmented and the size of the new merged heap will probably be pretty big (could be easily somewhere around 1GB or more depending on the resolution) which makes it harder to allocate as we need a continuous chunk of memory for it. Experimenting with this, it looks like the driver can perform this defragmentation when a big heap is requested, however, this new heap allocation may take many milliseconds to full seconds which makes it unusable in practice. And nobody says that we would not need to do this several times to get to the real highest usage.
Two hybrid allocation schemes can come from this. One is to allocate a big chunk first, hoping it will be enough for
most of the textures and use separate heaps for the outliers not fitting to the initial allocation. This, however,
has the problem of the MIN_ALLOCATIION_SIZE approach and wastes memory.
The other hybrid scheme is to not merge all heaps to one but to focus on small heaps because these are the most
problematic ones. This would mean that every heap under say 64MB would be merged so we would end up with only heaps
larger than that which means there would be more opportunities for aliasing. This seems like a relatively good idea but
I did not try it in practice.
ℹ️ It is now a good time to point out that all of these problems would go away if the API exposed the virtual memory directly and allowed us to over-allocate and commit only the pages that are used by our resources. To my knowledge the VRAM is already virtualized and each process gets its own virtual address space on the driver level. However, I do not know about any way to access this from DX12 on Windows (there is a way to do so on some consoles). This may or may not change in the future but right now it seems like the API creators do not want to lock out any HW or platforms that would not support this.
Conclusion
If you're still reading you have my deep admiration. The topic of transient resource management is very deep and I've just scratched the surface on many different aspects of it. However, the aim was not to give you a ready-made transient resource manager or teach you about all the ins and outs of DX12. Rather I wanted to share my experiences, point out some pitfalls, and show a basic idea for people to take inspiration from or just be happy about their own much better ones :)
P.S. If you end up in the realm of GPU memory management I cannot recommend enough the blog of Adam Sawicki and the AMD DX12 and Vulkan memory allocators he maintains.
References
https://www.asawicki.info/news_1738_states_and_barriers_of_aliasing_render_targets
https://www.asawicki.info/news_1724_initializing_dx12_textures_after_allocation_and_aliasing
-
DICE rendergraph talk - https://gdcvault.com/play/1024045/FrameGraph-Extensible-Rendering-Architecture-in↩
-
https://docs.microsoft.com/en-us/windows/win32/api/d3d12/nf-d3d12-id3d12device-createcommittedresource↩
-
https://docs.microsoft.com/en-us/windows/win32/direct3d12/memory-aliasing-and-data-inheritance↩
-
https://asawicki.info/news_1726_secrets_of_direct3d_12_resource_alignment↩